Using git-flow in a DTAP environment.
I’m a big fan of Git and I tend to use git-flow in most of my projects. A lot of people don’t like it, because it can be very tedious, but even if you only use develop and master branches, you’re already benefiting from it.
If you have multiple environments to deploy to, you can leverage git-flow logic to automatically deploy to these environments (in our case DTAP: development, testing, acceptance and production). Using a CI/CD server (like Gilab CI), we can auto deploy to specific environments when code gets pushed to the server.
Definitions
Let’s have a look at some definitions first.
git-flow
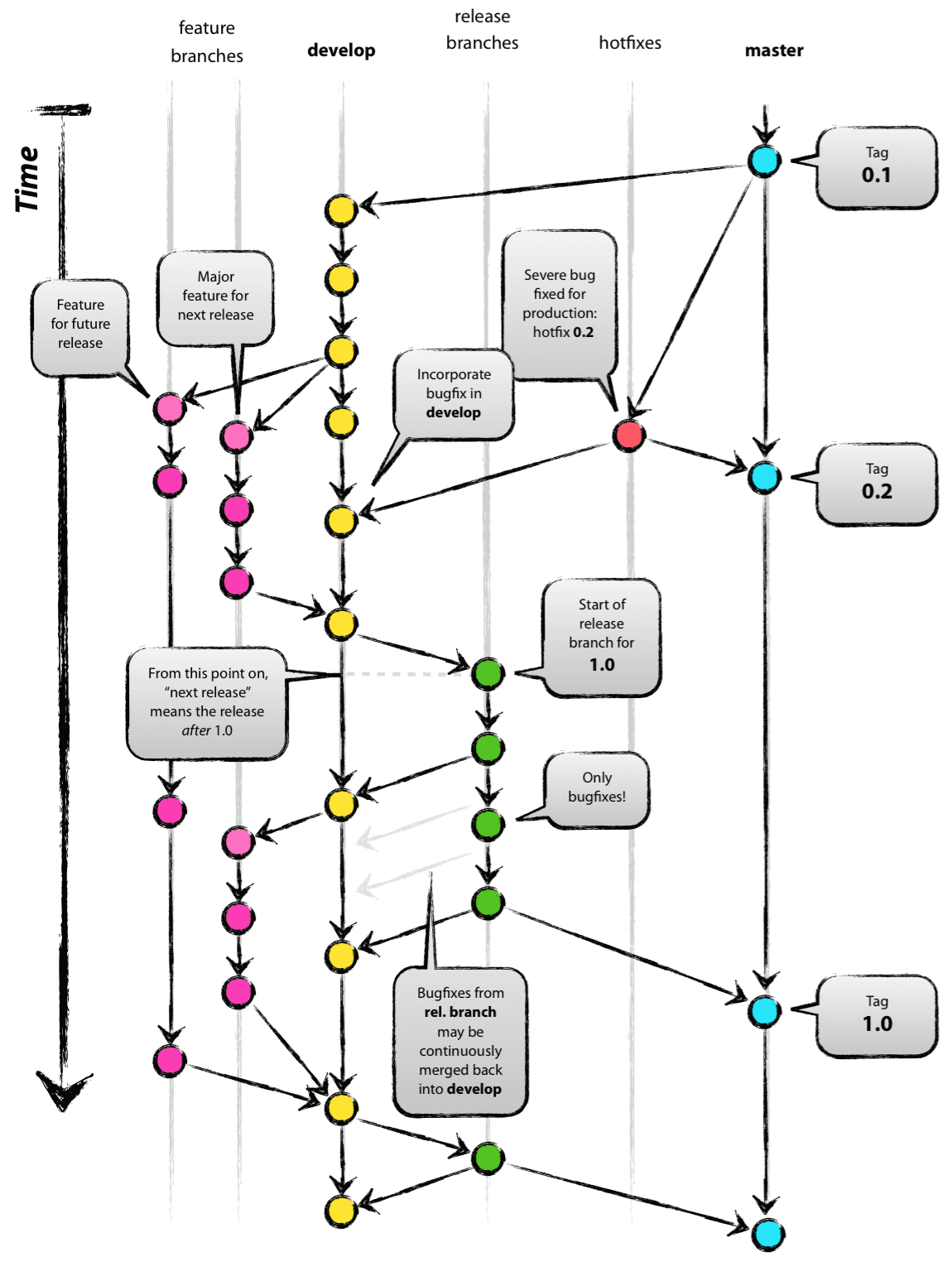
- develop
- The main development branch
- Ideally this branch only contains merge commits
- master
- This branch represents code in production
- This branch must only contain merge commits
- feature/*
- New development is done in a feature branch
- This branch is started from develop and will be merged back into develop when it’s done
- By using a feature branch, you can leverage merge request
- release/*
- This branch sits between develop and master (getting ready for a new production release)
- This branch is short-lived and totally optional
- hotfix/*
- When something is wrong in production, a fix can be produced via a hotfix branch
- This branch is started from master and will be merged into both master and develop
DTAP
- Development: local development
- Testing: beta server
- Acceptance: alpha server
- Production: live
Semantic versioning
Semantic versioning is a way of applying version to your software so it’s clear what impact it may have. As described on the homepage (semver.org):
Given a version number MAJOR.MINOR.PATCH, increment the:
- MAJOR version when you make incompatible API changes,
- MINOR version when you add functionality in a backwards-compatible manner, and
- PATCH version when you make backwards-compatible bug fixes.
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
When applied to git-flow, version are added in the form of git tags, and (for now) only the master branch receives tags.
When you merge develop or a release branch into master, you add a MAJOR.MINOR tag to it (only increment the MAJOR number is the change is big enough). When you merge a hotfix branch into master, increase the PATCH version.
In practice
Now we can configure our CI/CD system to start when we push code to a specific branch. In the Gitlab CI case, it is possible to limit jobs to branches with “only”.
- develop: auto deploy to Testing
- release/*: auto deploy to Acceptance
- master: auto deploy to Production
Tag based CI/CD
You could even limit job execution by using tags. Instead of starting jobs when you push code to a specific branch, you could let developers push to specific branches and kickstart a job by tagging it accordingly (which can be used to throttle builds and/or limit target environments).
Semantic versioning allows additional labels for pre-release and build metadata which we can leverage (1.0.0-alpha < 1.0.0-alpha.1 < 1.0.0-alpha.beta < 1.0.0-beta < 1.0.0-beta.2 < 1.0.0-beta.11 < 1.0.0-rc.1 < 1.0.0).
- develop: auto deploy to Testing
- No version tagging
- release/*: auto deploy to Acceptance
- Pre-release tagging triggers
- master: auto deploy to Production
- Minor.Minor.Patch tagging triggers
If you have extra environments (i.e. Education, Backup, Staging, etc…) you now can use even more pre-release tags:
- develop: auto deploy to Testing
- Pre-release tagging triggers
- 1.0.0-alpha
- etc…
- Pre-release tagging triggers
- develop: auto deploy to Staging
- Pre-release tagging triggers
- 1.0.0-beta.2
- etc…
- Pre-release tagging triggers
- release/*: auto deploy to Acceptance
- Pre-release tagging triggers
- 1.0.0-rc.1
- 1.0.0-rc.2
- Pre-release tagging triggers
- master: auto deploy to Production
- Minor.Minor.Patch tagging triggers
- 1.0.0
- 1.0.1
- Minor.Minor.Patch tagging triggers
Bonus points
Since we’re using semantic versioning and a build system, we can auto append build metadata to our version numbers. In the case of Gitlab CI, you can write a file containing a version number in the form of “1.0.0-rc.2+15” by using the git tag and the CI_JOB_ID variable.